Experiment - Determining Bad OCR via Automated Spellcheck
Misspelled words as indicator
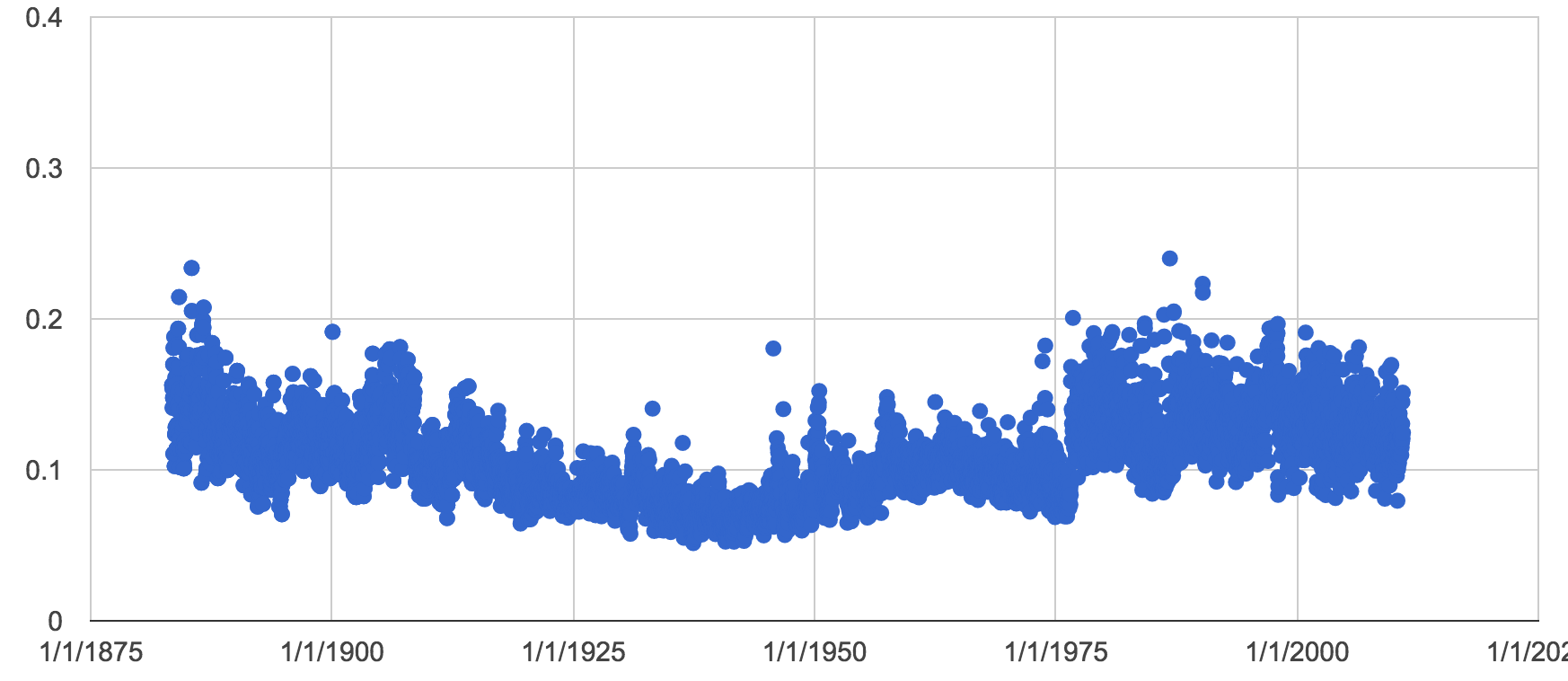
In ‘Bad Equity’, I ran an experiment trying to sonify the dirtiness of the OCR. It was suggested to me by Ben Brumfield (in DH Slack) that perhaps something like Aspell might be a useful avenue to pursue.
The following script runs each text file in turn through Aspell’s spell checker. The basic idea is to compare the number of ‘mispelled’ words (per Aspell’s English Canadian dictionary) to the total number of words in each document. Thus, the closer that ratio gets to 1, the worse the OCR.
The script
for f in *.txt; do
totalbadwords="$(cat "$f" | aspell list -d en_CA --encoding utf-8 | wc -w)"
totalwords="$(wc -w "$f")"
echo "$totalbadwords, $totalwords" >> "finalscore.csv"
done
(also on Github)
The script iterates through each text file. totalbadwords is a variable for storing the result of each file being run through Aspell’s dictionary, identifying ‘mistakes’, and then wc is used to count the number of these. totalwords just counts the number of words in each file. These values are echoed to a csv file so that I can open it in a spreadsheet or wherever to count, graph the result. Yes, I could do that in the script too I expect, but trying to write scripts that do one thing and one thing only.
output
Currently, the output is sitting on my laptop, and here on gdocs.
graphs
I tweeted some of the resulting graphs. In reverse order:
https://twitter.com/electricarchaeo/status/730781961506160642
https://twitter.com/electricarchaeo/status/730571625540820993
https://twitter.com/electricarchaeo/status/730571270870437889

interpretation
The consistent values in the .75 range are all editions where the Provincial Archives have inserted a placeholder for a missing edition.

Filter those out:
| Created: 16 May 2016 | Modified: 16 May 2016 | History | Permalink |
- Tags:
- soundbashing
- ocr
- newspapers